
2024年5月16日,中国计算机学会(CCF)推荐的A类国际学术会议ACL 2024论文接收结果公布,澳门新葡官网自然语言处理团队4篇论文被录用。国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)是自然语言处理(NLP)领域的顶级国际会议,同时也被CCF推荐为人工智能领域的A类会议,主要发表自然语言处理领域的前沿研究成果。本届ACL将于今年8月11日至16日在泰国曼谷举行。以下为4篇论文介绍:
第一篇论文:Hyperspherical Multi-Prototype with Optimal Transport for Event Argument Extraction
作者:张广军, 张虎, 王宇杰, 李茹, 谭红叶, 梁吉业
摘要:事件论元抽取旨在从文本中抽取指定事件的论元。先前的研究忽略了两种与论元相关的潜在归纳偏差:相同类型论元之间的语义偏差和不同类型论元之间的大间隔分离偏差。为了弥补这个缺陷,受原型网络的启发,研究团队提出了一种基于超球面多原型的事件论元抽取方法(HMPEAE,如图1所示)。该方法基于上述两种偏差预训练了一组类别原型,并引导BackBone模型学习论元表示。具体地,HMPEAE使用超球面作为原型的输出空间,通过最大化类间原型距离、最小化类内原型距离和利用类别标签语义先验知识三方面训练原型;在BackBone模型训练阶段,它将"论元-原型"分配视为一个最优传输问题进行优化。相比现有事件论元抽取方法,该方法实现了类间论元表示的大间隔分离,并有效表征了论元表示之间的类内方差,从而提高了事件论元抽取的性能。多个公开数据集的实验上验证了该方法的有效性。
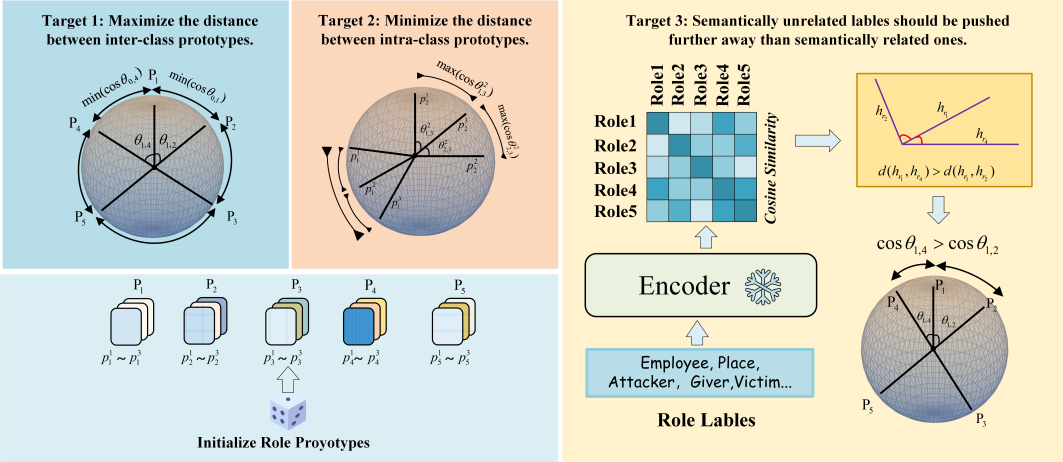
图1 基于超球面多原型的事件论元抽取模型
第二篇论文:Reinforced Causal Agent-Guided Self-explaining Rationalization
作者:赵云肖, 王智强, 李晓黎, 梁吉业, 李茹
摘要:合理化解释(Rationalization)旨在提升模型的自解释能力,其在自然语言处理、计算机视觉、推荐系统等研究领域已得到广泛的研究。现有大多数合理化解释方法在解释信息(Rationale)训练过程中忽略了对模型学习方向的有效控制,导致它们易遭受退化累积的影响。为了缓解这个问题,如图2所示,研究团队提出了一种新的智能体指导的合理化解释方法(AGR, Agent-Guided Rationalization),其核心思想是基于模型当前训练状态的好坏指导模型的下一步训练方向。具体地,该方法引入了因果干预算子来量化解释信息在训练过程中固有的因果效应,并利用强化学习过程细化模型的学习偏差。进一步,在上述强化因果的环境下团队预训练了一个智能体来给出具体的指导信号。研究团队从理论上分析了一个鲁棒的模型需要这样的指导,并从实验上展示了该方法的有效性,在多个数据集上进行实验,展示出所提的方法优于先前的State-Of-The-Art。

图2 基于强化因果智能体指导的合理化自解释模型
第三篇论文:InstructEd: Soft-Instruction Tuning for Model Editing with Hops
作者:韩孝奇, 李茹, 李晓黎, 梁吉业, 张子芳, Jeff Z Pan
摘要:模型编辑可以纠正大语言模型(LLMs)中的不准确或过时的知识。然而,当前模型编辑方法中存在的过度记忆问题、错误累积和知识冲突(如图3左)阻碍了模型的可移植性,即将新知识转移到相关的单跳或多跳内容的能力。为了解决这些问题,研究团队提出了InstructEd模型(如图3右),将软指令插入到注意力模块中,促进指令和问题之间的交互,实现对新事实的理解和利用。通过在LLaMAs和GPT2上的实验,该研究发现:(1) InstructEd可以提升模型对指令知识的利用能力,在单跳(多跳)模型编辑中分别提高了10%(5%);(2) 与早期在前馈神经网络(Feed-Forward Network, FFN)中编辑参数的方法不同,该研究验证了编辑注意力也可以实现知识更新;(3) 模型编辑与检索增强方法高度相关,检索增强可以帮助提高模型编辑的局部性和可靠性。
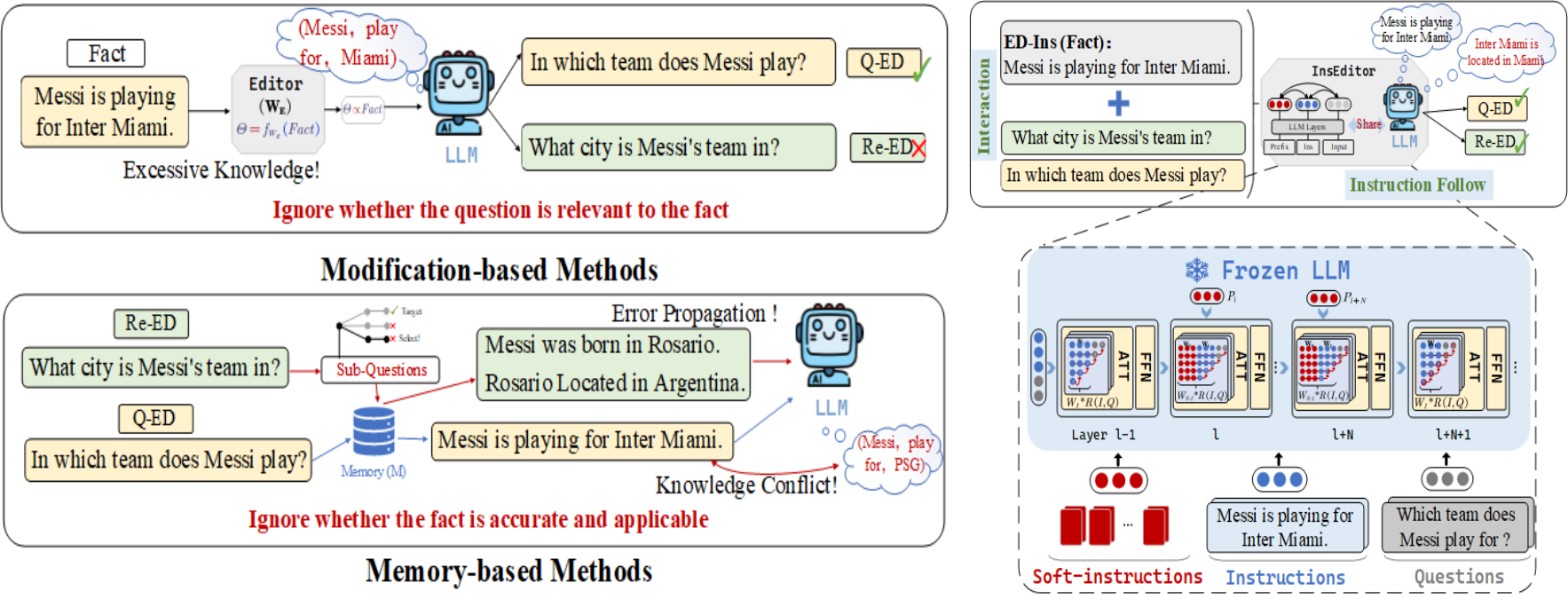
图3 现有方法缺陷(左)模型架构图(右)
第四篇论文:FRVA: Fact-Retrieval and Verification Augmented Entailment Tree Generation for Explainable Question Answering
作者:范越, 张虎, 李茹, 王宇杰, 谭红叶, 梁吉业
摘要:结构化蕴涵树能够展示从知识事实到预测答案的推理链,对于提升问答系统的可解释性具有重要意义。现有研究工作包括一次性直接生成整棵树或逐步生成证明步骤的方法。其中逐步方法能够利用组合性而推广到更长的步骤,但仍然面临较大的事实搜索空间和错误累积的问题,使得模型在多步骤情况下容易生成无效步骤。针对上述问题,研究团队受认知科学中双过程理论的启发,提出了一种基于事实检索和验证增强的蕴涵树生成方法,如图4所示。该方法包含两个系统,系统1通过事实检索模块有效剔除与目标假设无关的事实以减小搜索空间。系统2采用演绎和溯因双向推理的方式生成单个步骤,并通过交叉验证和多视图对比学习分别从支持性和相似性的角度增强单步证明步骤的可靠性,从而缓解错误传播问题。相比现有的蕴涵树生成方法,该方法能够生成更准确的结构化推理链,进一步提升问答系统的可解释性。
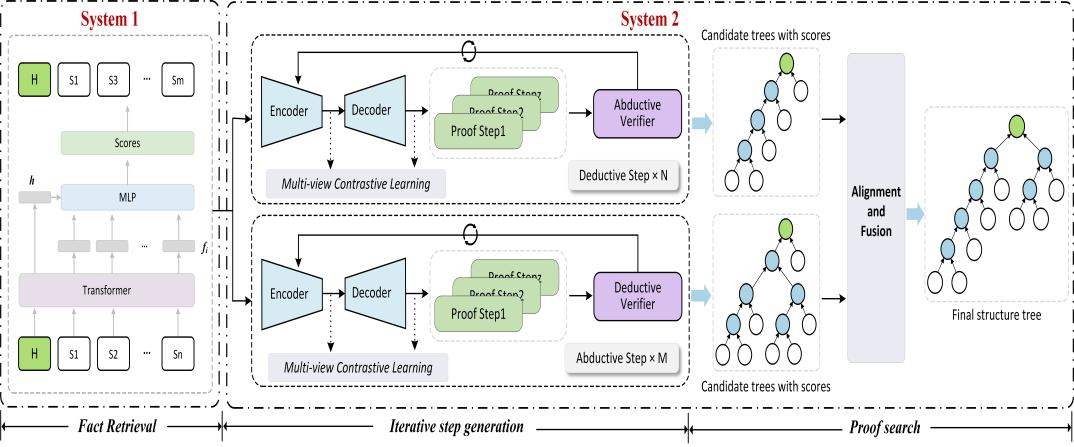
图4 基于事实检索和验证增强的蕴涵树生成模型